
Lessons learned from using Docker Swarm mode in production
We recently Dockerized the main part of our event processing pipeline using the 1.12-rc4 release. It’s been awesome using Docker in Swarm mode, and we’ve been really impressed with the ease of setup and use of Swarm mode. Our event pipeline processes around 220 million application errors per day, approximately 150k per minute, and performs a massive variety of processing tasks — it’s a critical piece of our infrastructure.
The new version of Docker Engine introduces native clustering capabilities, built directly into the daemon (as opposed to running a separate set of processes). This, in our opinion, positions Docker as a serious competitor in the container orchestration space (alongside giants like Kubernetes and Mesos), and will make building and operating large distributed applications easier for everyone.

A quick look at Bugsnag’s error processing architecture
As you probably know, Bugsnag is an error monitoring platform. As part of this, we have to accept, process, store, and display a large amount of events in near-real-time, containing errors for more than 40 different platforms that are written in over 16 different programming languages. That is no small feat. The event processing pipeline is a fairly large Node.js application that pulls items (events that contain errors) off of a queue, performs various types of work on each item, and stores it in our databases.
Why we chose Docker Swarm mode
We decided to modernize our setup when we saw the need to upgrade to a newer LTS Node.js version. After quickly realizing we were reinventing the wheel with a homegrown solution, we decided to revisit the space of container management. While ecosystems that were already well-established (Mesos and Kubernetes) seemed like good candidates, upon evaluating them it became obvious they were overly complex for our use case — to run a polling Node.js app on a fleet of nodes — and would have been an overkill to deploy and operate.
So we decided to try out Docker’s then-newly-released 1.12-RC4 engine for our needs. Setting up a Swarm mode cluster came down to simply bootstrapping the manager and adding workers, which is as easy as 3 commands:
docker swarm init(on 1 manager node)docker swarm join --token[manager_token] (on the rest of the manager nodes)docker swarm join --token [worker_token](on the workers)
Personally, it took me no more than 20 minutes to bring up a Swarm mode cluster — from reading the docs to having it ready for work. Compare that to my Mesos experience back in the day, which took about 2-3 hours of thoroughly reading through documentation for multiple complex components (ZooKeeper, the Mesos master, and the Mesos slaves). After that, it took me another two hours to fully bring up the cluster and get it ready to accept work.
The time savings from setting up and operating a Swarm mode cluster, combined with its spot-on UX and interface, sets Docker up as a serious competitor in the space, and truly enables container management at scale for the masses.
Tips for running Docker in Swarm mode
We’ve been running the event processing pipeline in production in Swarm mode for over a month now, and along the way we ran into issues that helped us uncover important lessons for working with this system. Here’s a list of key takeaways that are valuable to know before starting — they took some time to figure out, but have a significant impact.
Beware of issues in the network stack
We’ve coded our application to make it easy to deploy: instead of servicing inbound requests, it pulls from a set of queues. Outbound connections in Swarm mode work fine. However, when we started looking into adding services that dealt with requests on inbound connections (listening on ports), we quickly found the routing mesh feature of Swarm mode to be unreliable. The idea behind the routing mesh is to intelligently route service requests to machines that are running the service container, even if the host receiving the request isn’t running the container. This is achieved through a gossip layer between the workers in the pool that allows them to talk to each other, directing requests to the appropriate container. However, when we tested it out, the intelligent routing was very spotty, sometimes hanging during a request, and sometimes not even accepting inbound connections at all.
As it stands at the writing of this post, there are several open GitHub Issues related to this problem (we are tracking #25325), and the community is working hard to fix the underlying cause.
Have a solid labeling system
By labels we’re referring to Docker’s native labeling system — both for containers and the Docker engine itself. While the use case for container labels may be obvious, labeling the Docker daemon itself has some benefits as well. For example, we have automation in place that reads all tags of an EC2 instance at boot, and applies them as labels to the Docker daemon running on that instance. This is particularly helpful for knowing what role a specific Swarm worker has, what AutoScaling group it’s a part of, and other attributes we may use in the future when deploying services. In Swarm mode, when creating a service, you can use these labels in the --constraint-add flag (docs here) in order to set a service’s affinity to the Swarm nodes / engines that match the specified conditions.
Here you can see how we’ve chosen to label our Docker nodes:
[truncated]
Labels:
aws:autoscaling:groupname=swarm-worker-ondemand-new
name=swarm-worker
role=swarm-worker
roletype=ondemand
[truncated]
Partition your cluster into heterogeneous worker pools
We needed a way to ensure that resource-intensive apps would get the right type and amount of necessary resources it required. In our case, the event processing pipeline is mostly CPU-heavy, so it’s necessary for it to be able to run on all of the cores of an available Swarm worker.
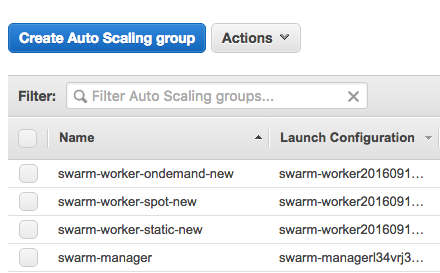
To address this issue, we decided to create multiple AutoScaling groups that would comprise the Swarm worker pool — on-demand instances (regular EC2 pricing), spot instances (low pricing, but instances come and go often), and static instances, running apps that can/will not move around too much and do not have such strenuous resource requirements).
Container, image, and log retention
Our event processing pipeline application produces a massive amount of log data, and during our first deployment of it onto the Swarm mode cluster, we saw the disks fill up in a matter of hours. In order to avoid this scenario, the intermediary solution (until we have centralized logging for the cluster) is to keep the last 5GB of all Docker logs. This seems to work okay for us.
But what about left over images and containers, you say? Well fortunately, other companies who have been running Docker in production have come up with solutions for similar issues we encountered. Spotify released an extremely useful tool which cleans up old, unused containers and images. The idea is to run this periodically (once or twice a day at our current workload type/deployment rate) on every Docker node.
Make sure to rescale your containers when adding new worker nodes
We discovered another interesting fact we thought was counter-intuitive. Right now, when a new worker joins the Swarm, it stays idle until the next user-triggered service event (create/scale). According to engineers at Docker, this is on purpose so a new worker node doesn’t get overloaded with a flood of new containers to it.
There are some scenarios where this would prevent unreliable operation, but we think it would be better if containers were rebalanced automatically when a new node joined.
Swarm mode open questions
Here are some of the things we still need to figure out that would help improve our experience with Docker Swarm mode. If you have an answer or can point us in the right direction, please send us a Tweet.
Fully automated cluster turnup
At the moment, the provisioning process for the Swarm managers is fairly manual, requiring us to bring up about three nodes and very carefully bootstrap them into having a Raft quorum. Certainly this process could be automated, but we haven’t prioritized it yet.
AutoScaling policies
In our previous setup, we would scale up the nodes based on queue length in our queue servers (Go/Redis) and scale them down based on CPU usage. The same could be done for the Swarm workers running our event processing pipeline code; however, that only solves part of the problem since there are two layers we now have to scale — the EC2 Instances themselves, and the Swarm containers comprising a service. We have not yet come up with a solution for the latter and are researching options.
Ideally, we would autoscale the containers based on queue length (growth rate beyond a certain threshold — scale up, cooldown period for a certain amount of time after which we would scale back down) and scale the Swarm worker instances based on CPU usage, since the event processing pipeline is CPU-hungry.
Rolling upgrades for Docker Engine and EC2 Instances
This might be a wishlist item (since we don’t find ourselves doing it frequently enough to merit an automated solution), but it would be very nice to be able to simply bake a new AMI, the completion of which would trigger a job that could swap out instances one or several at a time, such that we would be able to perform zero-downtime upgrades automatically. This can still be done, but right now it’s by hand.
Our verdict
In the end, we think that Docker Swarm is an amazing technology that will help engineers build and run distributed applications at scale with ease. While there are currently a few shortcomings, they are not deal-breakers for us, as the overall experience of using Swarm mode has been very positive.
The main benefits of Docker Swarm mode is the ease of cluster setup and the ease at which we were able to make changes to the entire stack of our event processing pipeline codebase. We are planning to launch more of our services on Docker Swarm mode very soon.
We hope that our story and the lessons we learned from using Docker Swarm mode in production is helpful to you, whether you’re just considering running it or are already running it and may have run into similar problems.
Again, if you have any questions, comments, or suggestions, please reach out to us on Twitter!