
Remove guesswork and save time prioritizing bug fixes
Bug fixes and building new features are always in competition with each other, and it’s common for teams to have a hard time deciding where they should spend their time when it comes to prioritizing these two conflicting, but equally important tasks.
One major problem is that prioritizing errors isn’t always clear. Figuring out how much negative impact a bug is really causing is an important question to answer because not all bugs are worth fixing.
That’s why having a solid strategy in place for prioritizing bugs is so important. In order to appropriately allocate your engineering resources on bug fixes and feature building, you need to understand the impact of errors on your application’s stability and on your customers. Then you can definitively say bugs are high enough priority that they should be scheduled into a sprint alongside your work on building new features.
Here’s a best practices guide for managing the prioritization of software bugs.
Get setup with smart stability monitoring from the start
To get off on the right foot, be sure to invest some time in setting up a robust system for detecting errors and monitoring stability. This will go a long way towards helping your team be proactive about bug fixes, and give them visibility into which errors cause the most harm. By thinking about your setup from the start, you’ll make it easier to prioritize bug fixes at the right time down the road.
Proactively detect application errors
It’s quite common to hear of engineering teams who mostly find out about bugs and fix them when a customer complains. This is a negative experience for the customer, and for the ones who do complain, there are probably countless others who gave up and churned from your product.
Proactively detecting errors when they happen can solve this problem and provide a better experience for your users. You’ll also have insight into how widespread errors are, so instead of reacting to whatever appears to be the greatest pain based on complaints, you’ll actually be able to fix the most harmful errors.
Use intelligent alerting to cut down on noise
When it comes to prioritization, a great place to start is by making your alerts smarter. Alert fatigue is something all engineering teams should be wary of, so instead of receiving a notification every time an error happens, opt to receive alerts for:
- New types of errors
- Errors occurring frequently
- Regressions
- Error rate spiking
This way you can stay focused on errors you haven’t seen before, or ones that might have a greater impact on your customers.
Group errors by root cause for visibility into a bug’s impact
You can increase visibility into the impact of each error by aggregating errors by root cause. A long list of error instances is better than nothing, but it really doesn’t offer much clarity into how frequently a given error is occurring, or how many users are being affected-key indicators into an error’s impact.
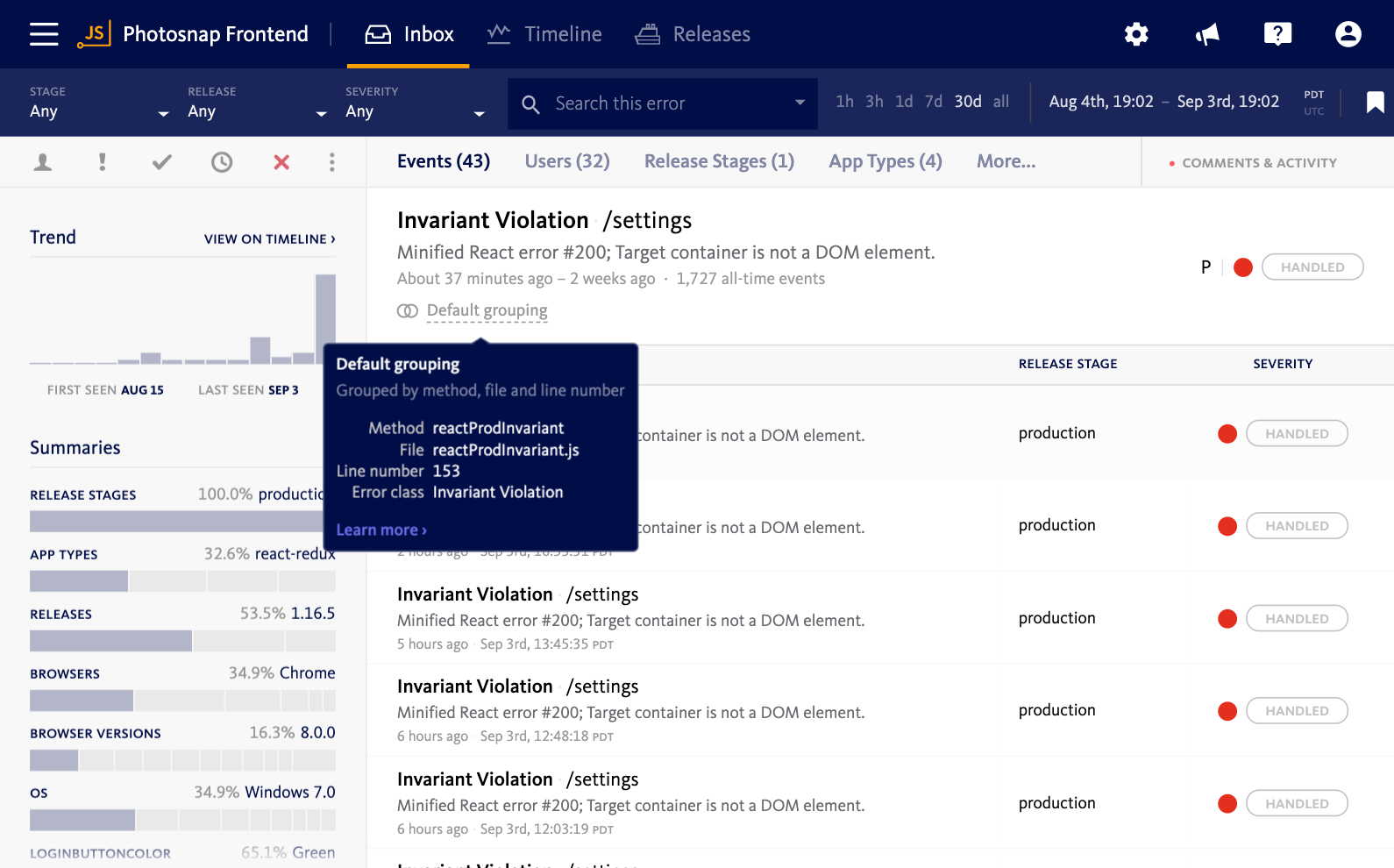
By grouping like-errors together, the ability to assess an error is much easier because you can see exactly how many times an error happened. This visibility gives you the information you need to prioritize bugs effectively.
Trace errors through your technology stack
Modern applications are made up of various systems, often built in different languages and using different technologies. Errors are not limited to manifesting within the borders of just one part of your app—a bug in your frontend code could be caused by a bug happening your backend code. If error information is spread through various systems, piecing it together can be a challenge.
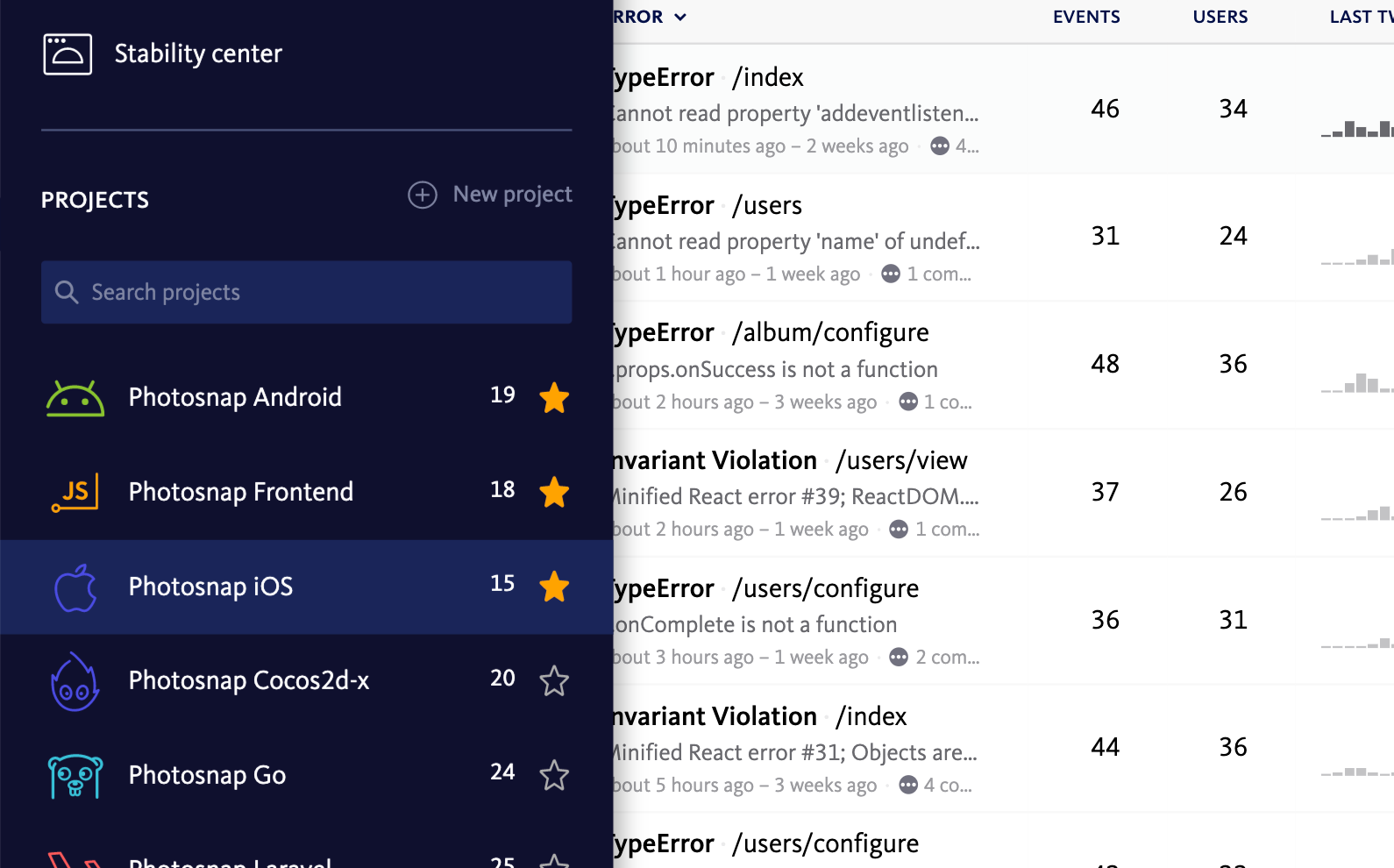
By bringing all your error reporting together in one place, you’ll be able to track bugs throughout your system and understand how widespread they are.
Focus your error inbox to keep it actionable
Now that you’ve configured stability monitoring to work for you, some simple actions for cutting down noise will help keep things actionable and bring focus to your prioritization efforts.
Train your system to understand which errors to ignore
There are some bugs you’ll never be able to fix, like bots spamming your application with nonsense form data and URLs. It’s a good idea to turn off notifications for this kind of activity by silencing these notifications. In Bugsnag, you can do this with the Ignore action and all future notifications for that error will be silenced.
Temporarily silence errors until they reach a critical level
There are also times when an error might be important to fix in the future if it becomes more prevalent, but until it reaches that level, you shouldn’t spend time thinking about it.
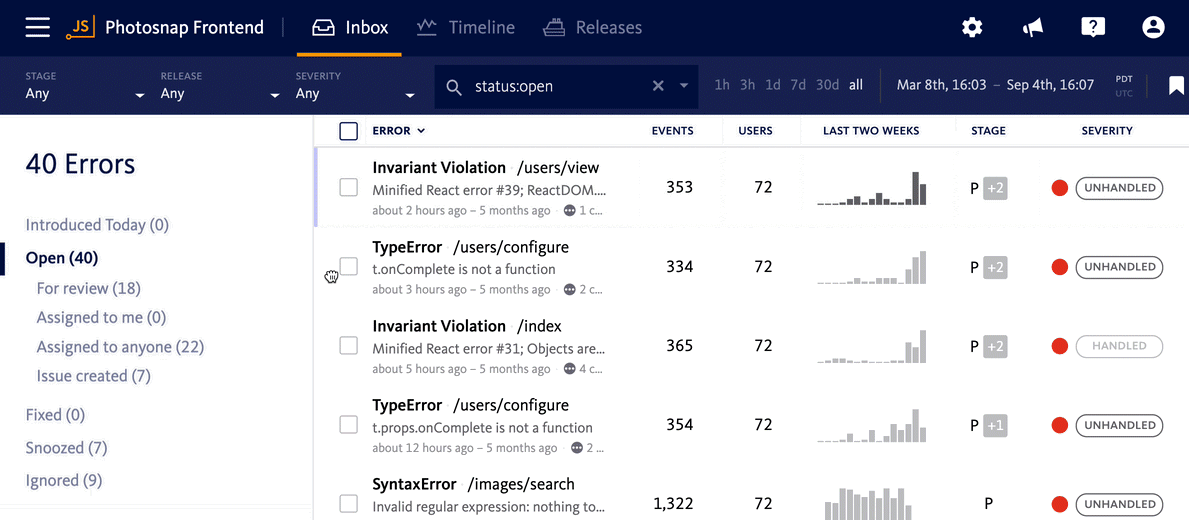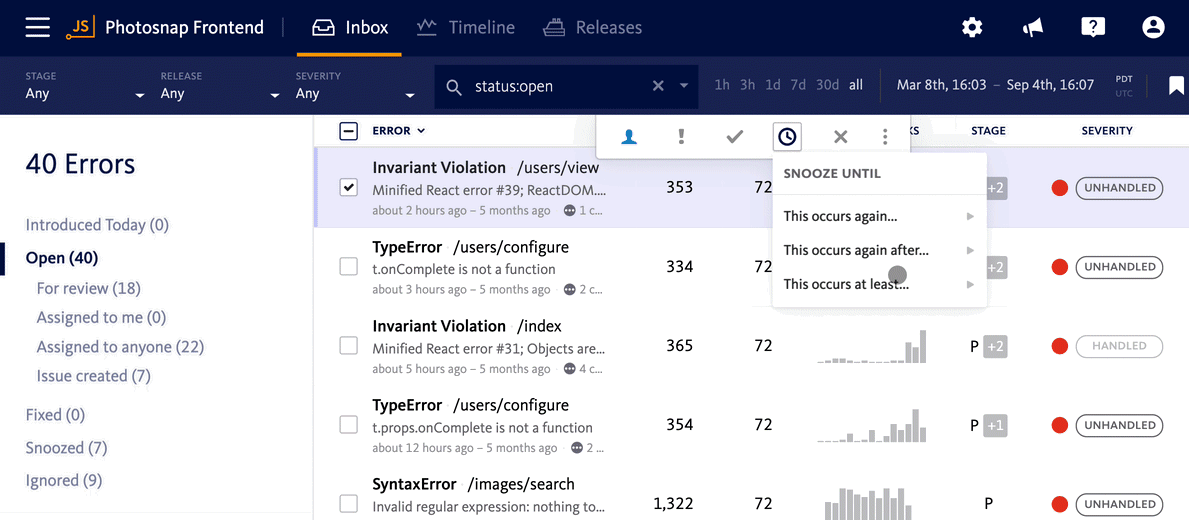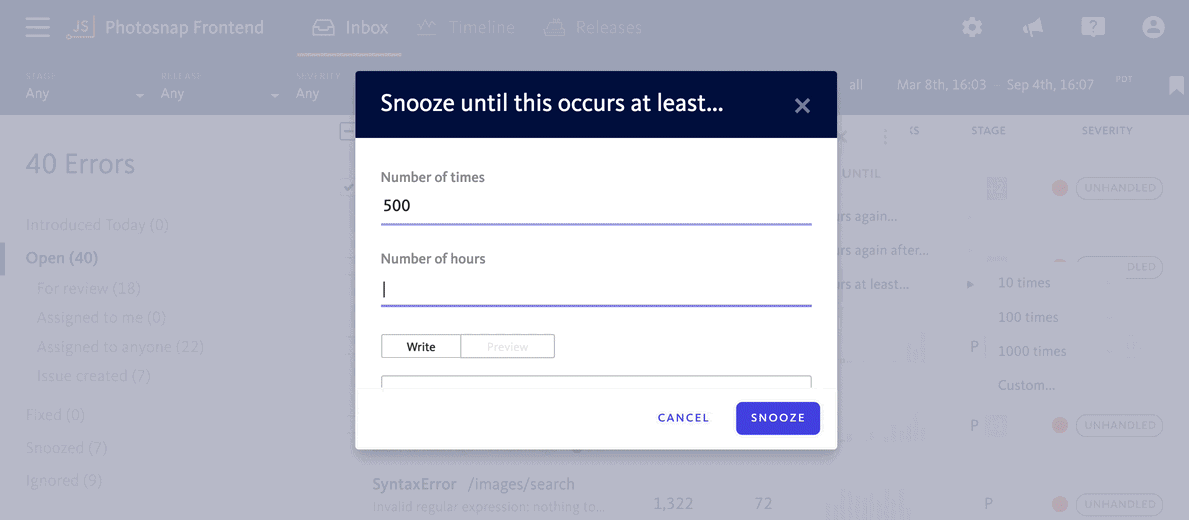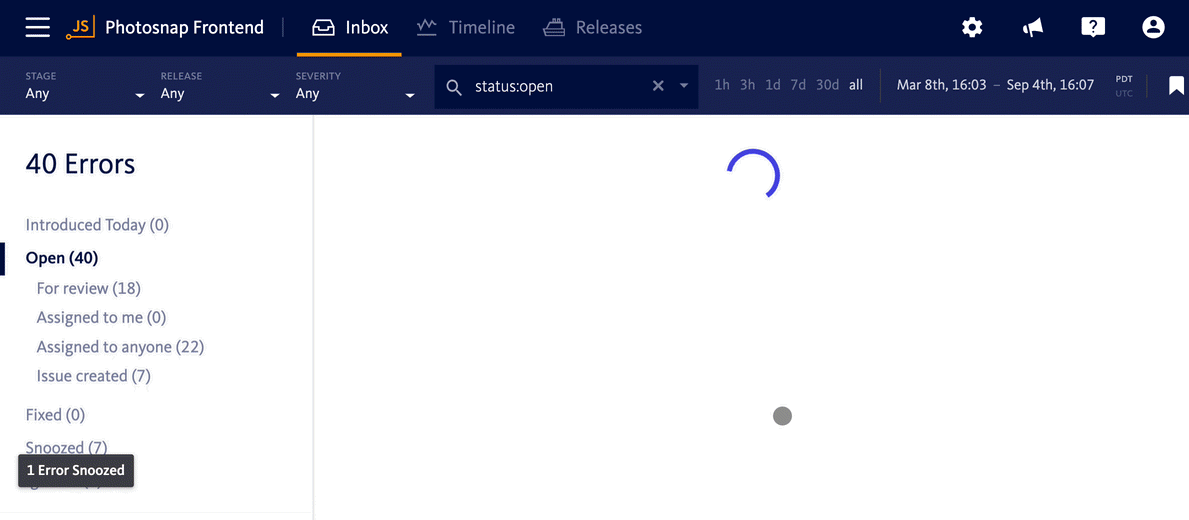
Rather than leaving those types of errors sitting in your inbox (which can take up mental space and detract your focus from errors needing immediate attention), snooze notifications for them until they reach a critical threshold.
Prioritize the most relevant errors first
Once your system is setup and error noise reduced, proper workflow and strategies will help you prioritize the most relevant errors first.
Focus on user impact
One of the most important things to consider is how much of your user base is impacted by an error. Generally speaking, a bug that only affects one user is probably less of a priority than one which affects hundreds. Mapping errors to users, in combination with grouping errors by root cause, is essential to this. In Bugsnag, for example, we show you how many users were impacted by a bug alongside the error frequency, and let you sort by these metrics so you can immediately understand how widespread an error really is.
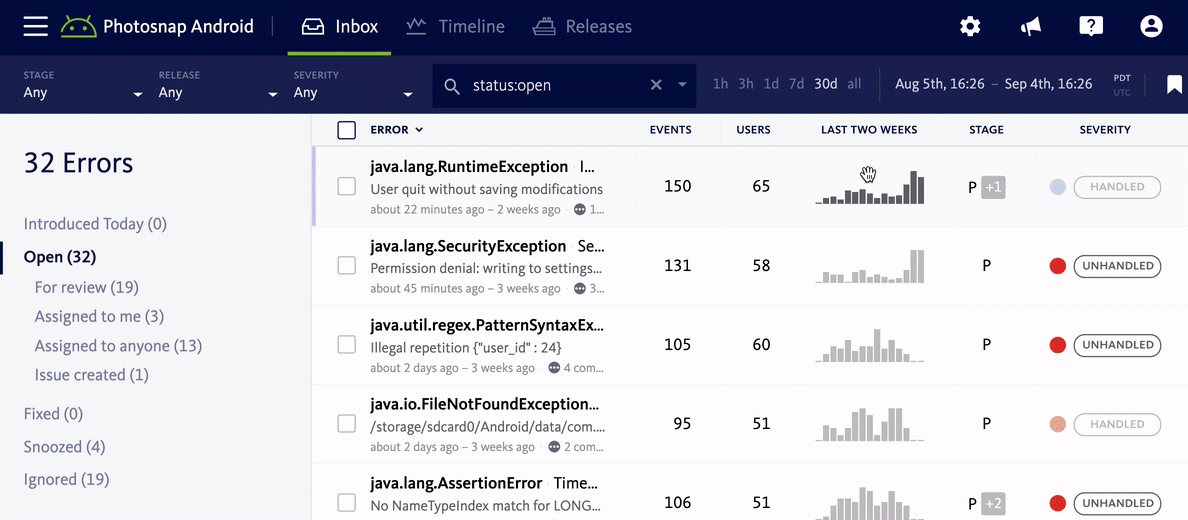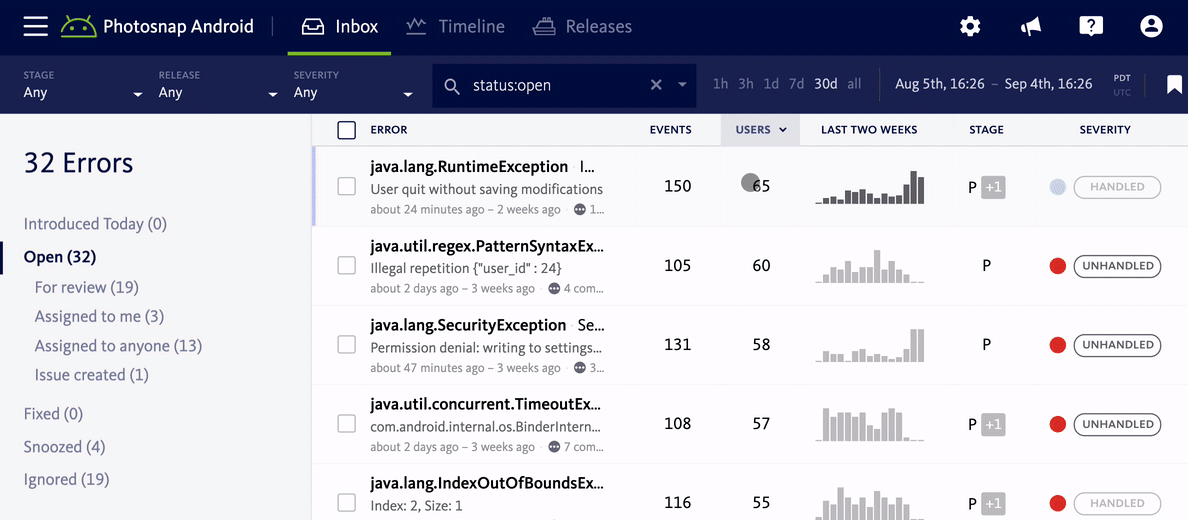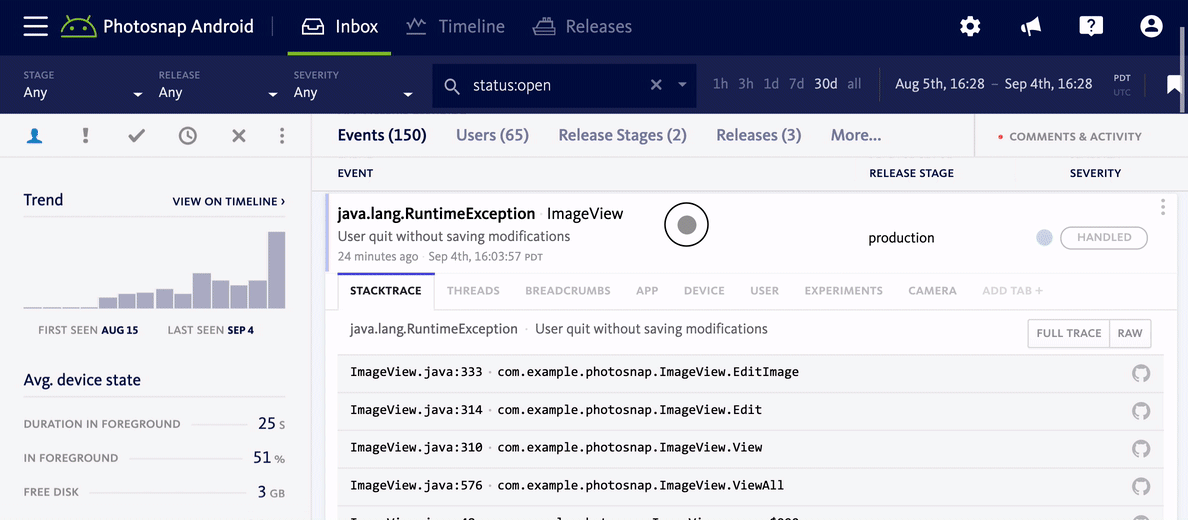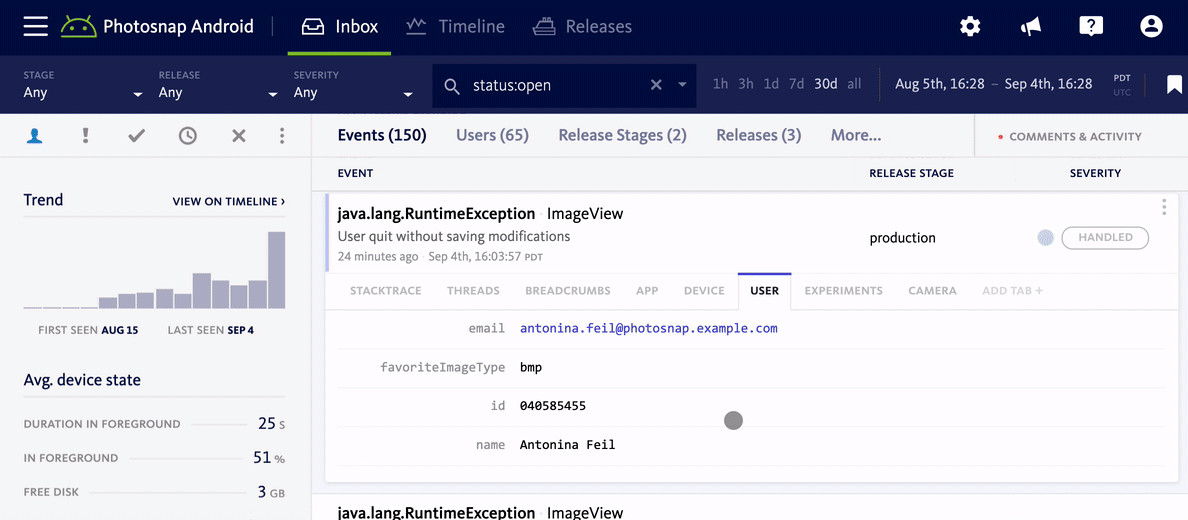
Focus on key areas of your code
Another prioritization strategy is selecting, in advance, certain areas of your code you want to monitor more closely. For example, you might want to monitor and prioritize bugs in the checkout portion of your application, or on the signup page more urgently. You can do this by passing in custom diagnostic data and then filtering to view all the errors impacting this area of your code.
Watch for errors affecting vip customers
Similar to focusing on key areas of your code, you can also watch for errors that impact your most valuable customers. You can pass in custom diagnostic data, like pricing plan, which will be attached to the error reports of all your customers. Then simply filter for customers on a specific plan level to view the errors they’ve experienced in your product.
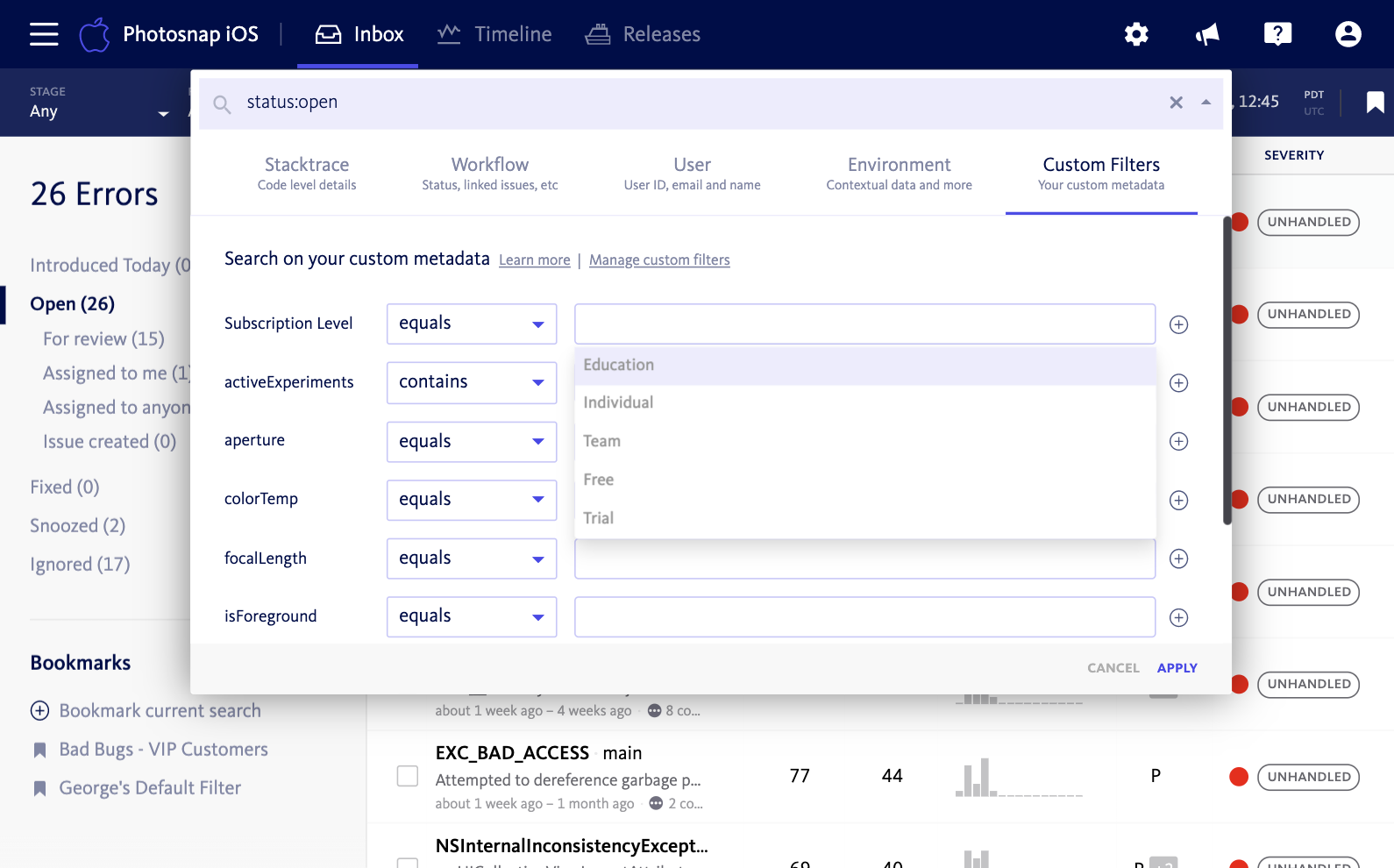
Concentrate on the most important releases
Another way to make prioritization easier is to only view errors in the releases you’re most interested in, like your latest or maybe two latest releases. That way you can focus on fixing bugs in the newest versions of your application since many of your customers probably will have upgraded, making supporting older versions of your app less important.
For JavaScript applications, you can use this same concept to filter down by browser versions as hopefully most of your users will have updated to later versions of their browser.
Prioritize errors by moving them into your debugging workflow
Once you’ve identified the most important errors to fix, you’re not quite done yet. It’s important to then figure out what to do with them by getting them into your debugging process. Be sure to have a debugging workflow in place to help you move forward with your prioritized errors and resolve them. Check out our debugging workflow guide guide for strategies to help you get started.
Using an application stability monitoring solution, like Bugsnag, can help you understand when you need to prioritize debugging alongside feature building. With best practices for getting setup and a streamlined prioritization workflow, you’ll save time and remove any guesswork from dealing with incoming application errors.