
Best practices for triaging software defects and bugs
We’ve collected some triaging best practices to help you ensure that your teams can quickly identify errors needing an immediate fix and ensure that lower priority errors are addressed promptly if they become more impactful in the future. While engineering teams differ greatly in their structure and internal processes, any team that is monitoring software stability will benefit from streamlining their error triaging practices.
At a high level, triaging bugs involves reviewing the errors currently affecting your system and sorting these errors into three general categories:
- Errors that need immediate developer action (rolling back a release, deploying a fix, etc.)
- Errors that do not need immediate action at the moment, but may in the future (if the error becomes more frequent, affects more users, etc.)
- Errors that will never need developer action and can be ignored safely
Our goal here is to help you develop smooth error triaging workflows for your engineering teams so that you can deliver the highest quality software to your customers.
Bugsnag Triaging Principles
Reactive vs. Periodic Triage
Before diving into several triaging best practices, let’s consider two general scenarios in which errors are triaged.
Reactive triage
Generally reactive triaging occurs when there is an issue that needs immediate attention, often one of the following affecting your system:
- A new bug
- An anomalous spike in bug frequency
- A bug in a critical area of your system
- A bug that was previously fixed and has now been re-introduced
- A release with a stability score lower than your stability target
In these cases, someone on your team should immediately triage the errors involved to understand the root cause, impact, and options for remediation.
We recommend configuring Bugsnag’s Alerting and Workflow Engine to notify you via team chat, email, or on-call alerting system when an error that needs immediate attention occurs so that you are able to triage it promptly. Bugsnag’s spike detection is especially useful for reactive triaging workflows.
Bugsnag’s Alerting and Workflow Engine is flexible and highly configurable, meaning you can define the specific criteria needed for reactive triage to occur. Some of examples of what’s possible with the Alerting and Workflow Engine:
- Have Bugsnag automatically create a PagerDuty incident if there is a spike in errors affecting your VIP customers or a core application flow
- Have Bugsnag automatically notify your team’s Slack channel if there is a new error introduced affecting your team’s area of a monolithic codebase
- Have Bugsnag call a custom webhook if there is any spike in errors across your entire project
To learn more, here are some helpful blogs on the following topics:
- Configuring Bugsnag to alert your team immediately of the highest impact errors affecting your systems
- How to monitor releases
- Fundamentals of stability management
Periodic triage
It’s unlikely that a reactive triaging workflow alone will ensure that every bug impacting your system is adequately reviewed. Some bugs are inherently lower priority and may not need immediate triage. Nevertheless, it’s still important that all bugs affecting your system are reviewed and prioritized regularly.
We recommend that teams regularly check their project’s Bugsnag inbox and ensure that all errors with a status of “for review” have been reviewed and triaged appropriately. Having someone on your team triage any bugs in “for review” once daily is a good initial target.
Periodic triage is especially important first thing in the workday, as there may have been new bugs detected outside of working hours that did not rise to the level of needing reactive triage.
Start triaging with the “For Review” filter
Bugsnag’s “for review” filter surfaces all of the errors that need to be triaged to determine impact and appropriate next steps. As your team determines the impact of each error in the “for review” state, each error should be moved to an appropriate workflow state using Bugsnag’s workflow actions. In general, workflow actions are used to categorize bugs as needing an immediate action (create an issue, assign, etc.) vs. potentially needing an action to be taken in the future (fix, snooze). We’ll discuss best practices for a few key workflow actions in more detail below.
For more info on error workflow states in Bugsnag, visit our docs page Error Status and Actions as well as this blog about Managing the status of errors in your inbox.
Triage your way to Bugsnag Inbox Zero
Bugsnag Inbox Zero means that you have triaged all errors in the “for review” state and therefore have no more errors to review. This is a significant target because it means that your team has taken appropriate actions to remedy all critical bugs and has determined the criteria for actioning all lower priority bugs in the future.
Once you have reached inbox zero, you can expect that errors will only be surfaced by the “for review” filter in a few key scenarios: if they are newly introduced errors, if they were previously snoozed and have exceeded their snooze threshold, or if they were marked as fixed and have occurred in a new release of your software. In all of these cases, these are bugs you want eyes on. By achieving inbox zero you ensure that you don’t end up with bugs your team has already reviewed and deemed low priority drawing attention away from these more urgent bugs.
It’s a great feeling to achieve inbox zero, knowing that you’re on top of all of the errors affecting your system. Teams that regularly achieve inbox zero are more likely to be actively engaged with the process of periodically triaging new bugs, ultimately leading to impactful bugs being fixed at the appropriate time.
Tips for Effective and Efficient Bug Triage
Determine a bug’s “Impact” using your team’s terms and concepts
A central question during triage is “what is the impact of this bug?”. By default, Bugsnag gives you insight into key dimensions that help to determine each bug’s impact. These include error occurrence counts and frequency trends, number of end-users affected, distribution across end-user device types, and many, many more. Even so, it’s likely that there are unique concepts from your system and business domain that could help you gain even more insight into each bug’s impact.
Some questions to consider and discuss as a team:
- Which concepts come up when your team talks about a bug’s impact?
- Are there concepts unique to your business’s domain that would help determine a given bug’s impact?
- Are there concepts unique to your software delivery process that could help too?
Once you’ve identified these concepts, you can almost certainly incorporate related information into your Bugsnag crash reports, enabling you to quantify each bug’s impact however it is most meaningful to your team and your business.
Some examples to get you started:
- Include A/B test cohort information as crash metadata, allowing you to determine if an error is affecting users in a particular A/B test cohort more than others
- Include feature flag metadata to inform how you roll out new features
- Include metadata relating to affected user subscription tier, integration depth, or other indicators of business impact, allowing you to see how often each error affects end-users across these dimensions
These examples are just a starting point. What other information could your team consider to best determine each bug’s impact?
For more on this topic, check out this guide on Advanced Features in Bugsnag and this blog about Monitoring errors in experiments with custom filters for arrays. And for a deeper dive, check out this presentation from Android Tech Lead at Square, Pierre-Yves Ricau, on tips for customizing error reports in Bugsnag.
Use shared bookmarks to create the most impactful inbox for your team
Bugsnag’s “for review” filter will show you all of your project’s errors that require triage. But what if you are working in a monolithic codebase and only responsible for a subset of the errors that are reported to the Bugsnag project?
In this case, we recommend using Bugsnag’s search and segmentation features to create a bookmark that will show you only the “for review” errors relevant to your part of the codebase. In cases like this, it can be helpful to make this a shared bookmark so that everyone on your team has easy access to it. We also recommend encouraging members of your teams to set this bookmark as their default view of the Bugsnag inbox. In this way, you’ll all have a consistent view of the subset of the errors from the monolith that your team is responsible for triaging.
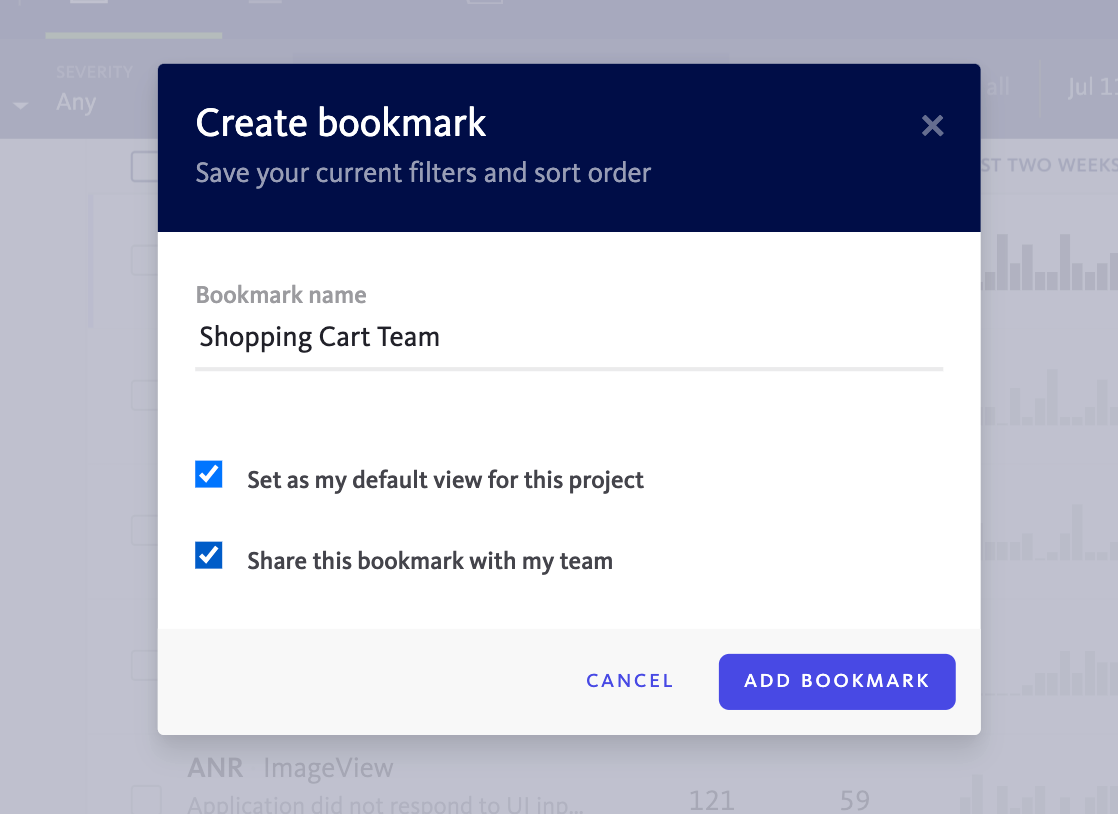
To learn more about searching for errors and configuring shared bookmarks, you can refer to this blog about Error Search in Bugsnag and this blog about Creating Bookmarks in Bugsnag.
Use snooze rules for low impact errors
During triage, it’s not uncommon to review errors that are relatively low impact and don’t need to be fixed with any immediate urgency. In these situations, the key question to ask is, “what would need to change about this error’s impact for us to prioritize a fix?”
Often the answer to this question will involve an absolute number of additional occurrences of the error, a frequency of occurrences over some time period, or a time in the future after which the error is no longer expected to occur. In all of these cases, these criteria can be expressed using a snooze rule. Snooze rules are great for keeping up with errors that are initially low impact but may become more severe in the future.
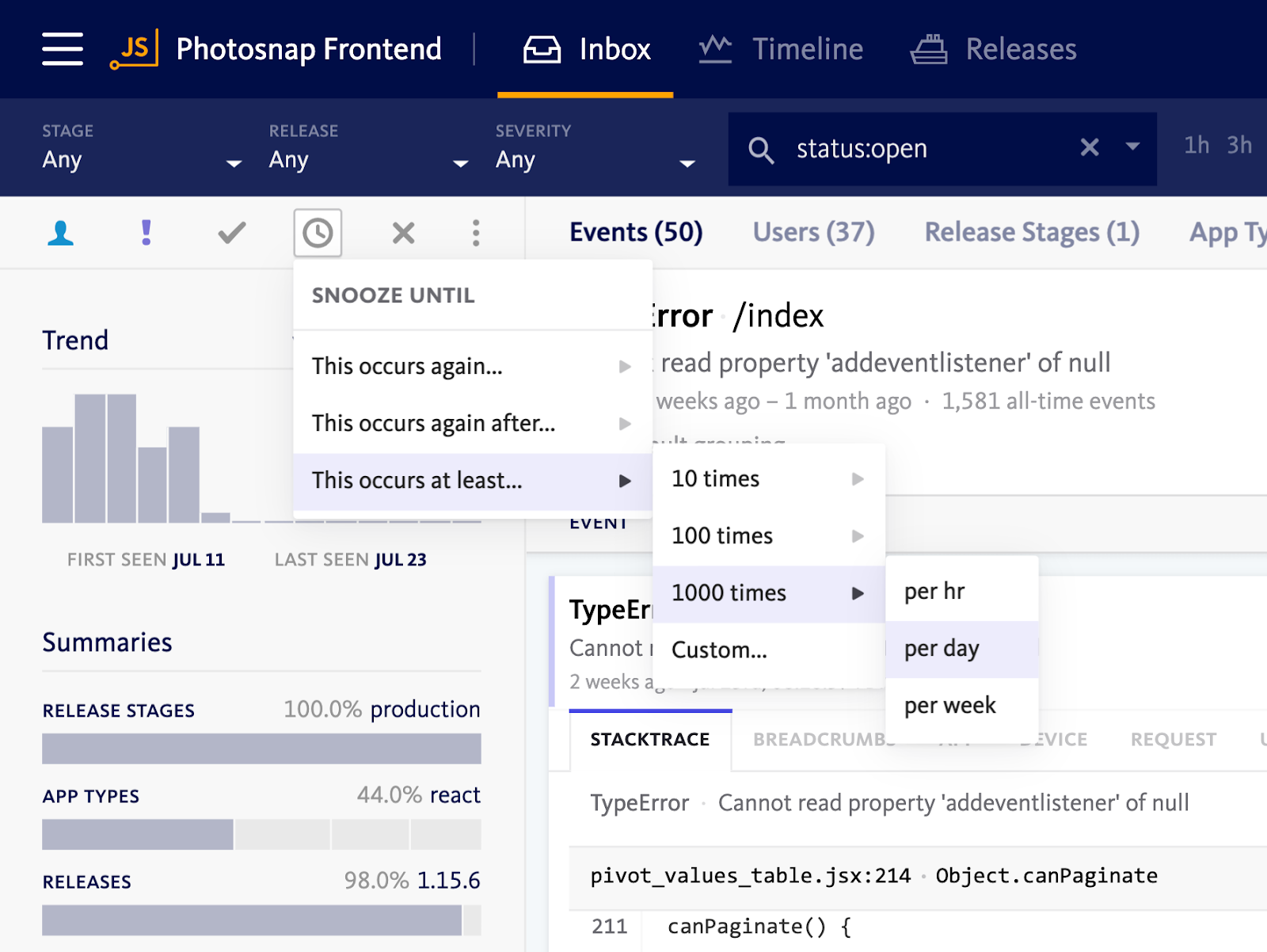
Once you’ve snoozed an error, it will only return to the “for review” state if the snooze threshold you specified is reached. At this point, it’s often worth prioritizing a fix.
Create a ticket in your issue tracker when a fix has been prioritized
If during triage a bug is determined to be impactful enough to warrant a fix, we recommend creating a ticket in your issue tracker to capture that work.
We recommend creating a ticket in two key scenarios:
- When the bug is urgent enough that an immediate fix is necessary. If you’re working in sprints, this means creating a new ticket and bringing it into your current sprint.
- When the bug is not so urgent that it needs to disrupt ongoing work but it is urgent enough that it will be worked on as soon as engineering bandwidth is available. This typically means prioritizing the fix no later than your next sprint.
In either case, creating the ticket in your issue tracker from within Bugsnag couldn’t be easier. From the error details page click the create issue button to create a ticket corresponding to the work needed to fix the bug. Just to make sure you’ve integrated Bugsnag with your issue tracker, you can refer to this product guide to get you started on that.
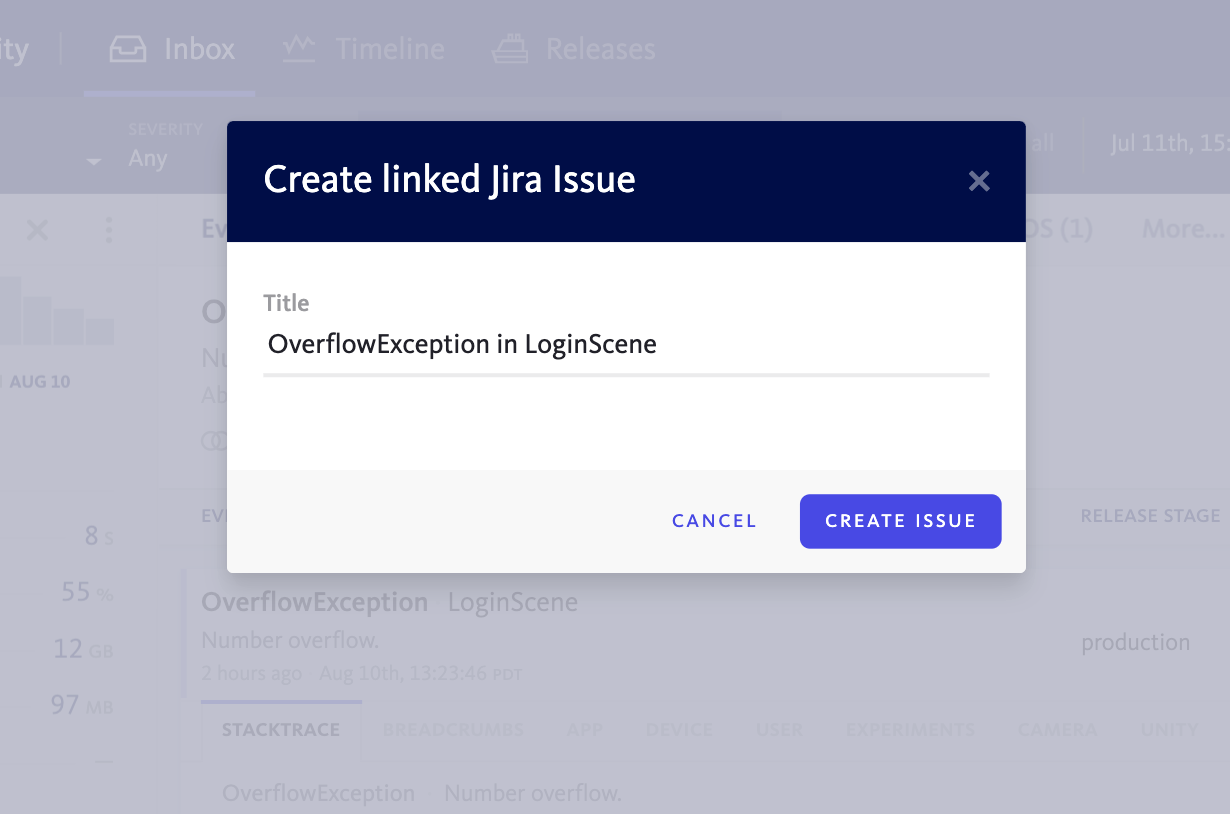
Avoid long-standing issue tracker tickets
For any bug that is not yet impactful enough to warrant a fix within the next sprint, we recommend you don’t create a ticket for it in your issue tracker yet. In this situation, the error is likely a better candidate for snoozing than issue creation. Remember the key question “what would need to change about this error’s impact for us to prioritize a fix?”. Represent the answer to that question as a snooze threshold. If that snooze threshold is ever reached in the future, then it’s a perfect time to create a ticket and prioritize the fix.
Why not create an issue tracker ticket the moment each new bug occurs? For many teams, there will be bugs that aren’t worth fixing in the near future. But crucially, if these low priority bugs begin occurring more frequently or affecting more users, they will become candidates for more urgent remediation. By preferring snoozing over issue creation in these cases, you can be confident that your lower priority bugs will be re-triaged if they ever become more impactful. While issue trackers are generally great for building long term priority-ranked roadmaps, longstanding bugs are a special case – their impact (and therefore priority) can change in an instant. While this context is generally lost within an issue tracker, it is readily available within Bugsnag.
As part of our team planning meetings, we check in on any Bugsnag errors with linked issue tracker tickets, making sure that these either have a fix in progress or are pulled into our next sprint.
Use comments
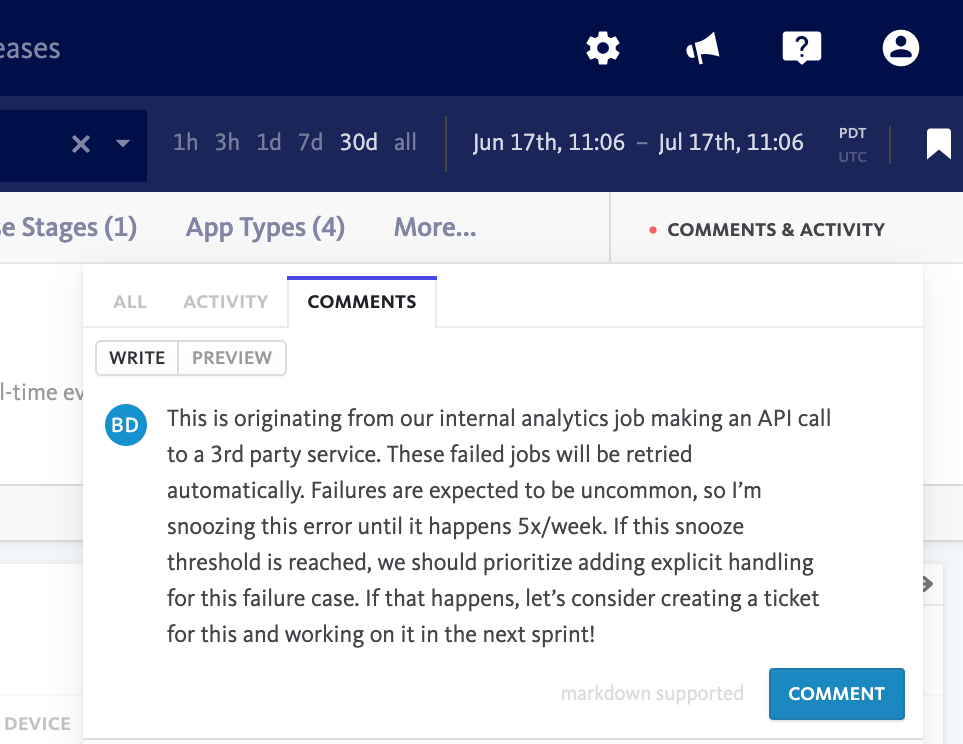
When triaging, whether you decide to snooze an error, create an issue for it, or take another workflow action, it’s often valuable to add a comment detailing your thought process.
It’s important that your teammates understand any context that has informed your triaging decision. Maybe you spent some time investigating the bug and determined that it’s unlikely to affect more users – what led to that conclusion? Maybe in the course of investigating a tricky bug, you began forming a hypothesis about its root cause – that’s definitely worth recording.
In the case of snoozing an error, it’s helpful to include a note about why you’ve chosen the specific snooze threshold and what you think should happen if the threshold is ever reached.
Whenever you take a workflow action on an error, consider whether there’s any additional information you can record as a comment. This will save time and prevent duplicated effort across your team, and often it will help encourage collaboration and discussion within the team.
Best practices for error triage process development
Make consistent and accurate bug triage a performance target
Each of your Bugsnag projects should have an owner, someone on the team who is ultimately accountable for the health and stability of the given project. This person doesn’t always have to be the one triaging or fixing bugs themselves, but they should be accountable for making sure their teams are following a reliable process for ensuring all “for review” bugs are triaged promptly and appropriately. Generally, it makes sense for this to be someone in an engineering leadership role on the team. Beyond this, work to develop a sense of ownership around application stability across the entire team.
Create a rotation for bug triage responsibilities
On your engineering team, who is responsible for triaging bugs today? There are plenty of valid answers to this question. What matters most is you have an answer that is well understood within the team. Consider a daily or weekly rotation, where each engineer on the team takes their turn triaging outstanding bugs. Depending on how your team plans, builds, and releases software, there may be multiple people in various roles who have a stake in this triaging responsibility. In these cases especially, clear communication is crucial – see the recommendations on using comments to record key context and decision points above.
Define a clear process for ownership of newly introduced bugs
Consider how the responsibility for managing errors in new releases fits with your triaging rotation. At Bugsnag, regardless of who is generally responsible for triaging errors on the given day, whenever an engineer deploys to production, the deploying engineer is responsible for ensuring their release goes smoothly. This includes reactively triaging and responding to errors that have been introduced as part of the release.
By contrast, the engineer on triage rotation is primarily responsible for periodically triaging all other errors that have entered the “for review” state. These errors will typically belong to one of the following categories:
- errors that have occurred for the first time but are not associated with a recent release (e.g. an uncommon edge case in a long-standing part of the codebase)
- errors that were previously snoozed that have been automatically moved back to the “for review” state because their snooze thresholds were reached (e.g. an error that has occurred 10x per day)
- errors previously marked “fixed” that have occurred in a subsequent release
For more information about the features available for monitoring release stability with Bugsnag, you can read this blog about The Stability Center and this blog about Stability Scores.
What if we have too many errors to review?
You may be thinking, “this all sounds great, but we have so many errors that need to be reviewed; putting these suggestions in place and getting to inbox zero sounds like a lot of work.” Here are some tips we’ve seen work well for teams needing to get their inboxes under control.
Refine the list of “for review” errors with a shared bookmark.
We often recommend starting by triaging high impact errors that have happened recently. For example consider searching your project for bugs that:
- have status “for review”
- occurred in a production environment
- in the last 7 days
- have a severity of “error” (as opposed to warning or info)
- and were unhandled (see our blog on unhandled errors for more info)
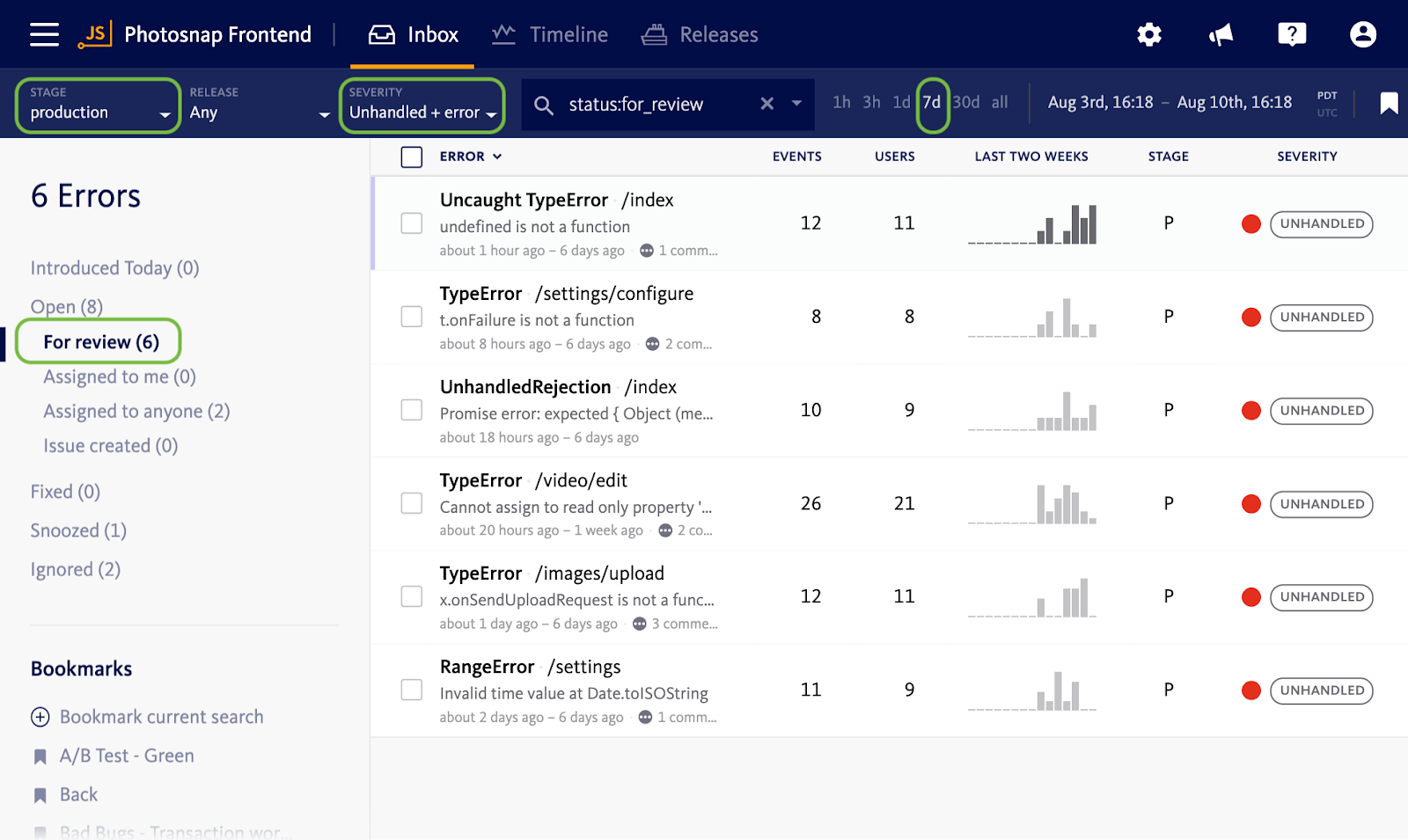
Applying these filters will show you the subset of your “for review” errors that are likely to be of higher priority. This refined set of errors will be less time consuming to triage down.
As with all filtered views of your project’s errors, this refined “for review” filter can be saved as a shared bookmark. By doing so, the list of errors to triage will always be a single click away for you and your entire team. You can even recommend that each team member set this shared bookmark as their default inbox view.
Over time, as your team gets up to speed with daily triaging and begins consistently hitting the daily inbox zero target, you can update this shared filter to be less restrictive. Consider expanding from 7 days of history to 14 days. Consider including “warning” and handled errors as well. Continue from there, eventually expanding the filter to include all errors that have the potential to be actionable for your team.
For more details on searching for errors and configuring shared bookmarks, see this blog on Error Search in Bugsnag and this blog about creating Shared Bookmarks.
“Fix” everything
In rare cases, the suggestions above don’t go far enough. If inbox zero still feels unreachable, we sometimes recommend marking all of your outstanding errors as “fixed”. This will get you to inbox zero temporarily. This creates the perfect opportunity to build daily triaging momentum within your team. If one of these fixed errors happens again in a future release of your software, the error will return to the “for review” state, at which point it can be triaged appropriately. This will help you stay at inbox zero on a daily basis. A less aggressive version of this involves marking errors that haven’t occurred for a few weeks as fixed.
You should avoid making this a regular practice, but in rare cases, it’s the best way to get your inbox under control if it hasn’t been properly triaged.
Closing thoughts
The insights and workflow actions provided by Bugsnag are flexible enough to support triaging workflows for engineering teams of all sizes, organizational structures, and system architectures. We hope you’ve found these recommendations useful as you reflect on your team’s approach to triaging bugs. The ultimate goal is to help you focus on the most impactful work at the present moment – whether that’s promptly fixing a critical bug or optimizing the stability of your next big feature.
If you’re interested in learning more about error triaging, I’ll be hosting a webinar on August 18, 2020, where I’ll demo these strategies for you in the Bugsnag dashboard. We’ll have a live Q&A session at the end, so if you have any questions I’d be happy to answer them then. Register for the webinar or catch the on-demand recording here.