
Modern approaches to managing legacy code
Most software products will have at least one legacy codebase that developers avoid because they are terrified of breaking it, but how do you go about fixing it?
First things first, the undisputed textbook answer on how to deal with legacy code is Working Effectively with Legacy Code by Michael Feathers. It takes a pragmatic approach to cleaning up your codebase through the use of test and incremental refactoring, and contains many techniques and examples. I highly recommend reading it.
Our options for working with legacy code
We have three options when faced with the challenge of updating a traditional legacy system:
- We leave the old code alone, and write more legacy code. Being the path of least resistance, this is by far the most common approach. It is also the wrong approach, as this makes the code harder to maintain in the future.
- We set aside time and resources to rewrite the legacy system from scratch.
- We approach the system pragmatically and slowly and incrementally improve upon it.
As developers, when faced with a big ball of spaghetti mud, we’re tempted to re-write the entire application from scratch rather than try to fix the old one. Fixing a large legacy system using the techniques and disciplines described in Michael Feathers’ book could take years of effort by skilled engineers, but we’re sure we could rewrite the gorram thing in a few months if we could only use SuperFramework v4.2!
The overhead of rewriting legacy code
What we often fail to take into consideration is non-technical or operational:
- Resourcing: We would need the same developers maintaining both the old system and the new. They are needed on the old codebase because they know it best, and will be the most productive in this horrendous environment. They are needed on the new system because they have the insight (and hindsight) needed to design the system properly. Adding more people to the team is tempting, but be careful not to overestimate the productivity improvements of adding more people – in particular in the short term.
- Ops: Have you got the required resources and infrastructure to deploy another service? Is your deployment process mature enough to incrementally develop and deploy your new system alongside your legacy system to mitigate risk?
- Sign-off: Are you responsible for making the decision of re-doing the system, or do you need approval from a higher-up? If they are non-technical, can you provide them with the necessary motivation and metrics they need to sign-off on your proposal? One way of measuring the problems that your legacy systems cause is monitoring the errors that your system generates. For most legacy systems these numbers will be terrifying quite motivational.
- Overhead: Design meetings, establishing processes, reflecting changes in one system in the other, office politics etc. could easily take man-years for medium to large scale projects.
The above list only mentions some of the known unknowns, and is by no means exhaustive. In an endeavour like this we will always discover unknown unknowns that will further complicate the rewrite. Usually rewriting a system is an expensive approach, and should be used as a last resort.
Methods for mitigating risk when refactoring legacy code
Risk is the reason we don’t want to touch our legacy code. You don’t want to be the reason why your company loses $40 000 an hour because of a faulty and hard-to-read if statement. Risk is also the reason why we should touch our legacy code. Bad legacy code leads to more bad code, and unless you actively take action to improve your legacy code you risk ending up in an even worse position.
Luckily, there are a few modern tools and techniques we can adopt to mitigate some of the risk that come with legacy services.
Using continuous delivery as a safety net for legacy systems
Before starting to rewrite and deploy a legacy application, we would like a safety net that will catch us if we accidentally deploy a bad build. Of course, we hope that we won’t ever have to use this safety net but we will feel a lot safer knowing that it’s there. This safety net is being able to quickly and easily deploy and revert to a previous build. To be able to do this easily we will have to spend some time developing a deployment process and a release pipeline. The end goal in continuous delivery is being able to do a release in one step, and a deployment in another.
Detect unexpected behaviour in legacy code with error monitoring
Suppose you work for a business that has a large legacy service in production. How do you know just how well your legacy service is holding up? Gut instinct? The number of rants you overhear from the developers? Do you go by the number of bugs in your issue tracking system, or perhaps by the number of support requests that come in?The issue with all of the above is that they all depend on a source external to the application itself to tell us that something is wrong. With an error monitoring tool like Bugsnag we get notified in real time whenever our application behaves unexpectedly. Error monitoring comes in really handy when checking for regressions. Bugs can be marked as fixed, and if they reappear we get notified about the regression and should perhaps rollback to an earlier version. Similarly, either by using as-is or by integrating Bugsnag with your favourite issue tracking service, you can monitor the progress of improving your legacy codebase.
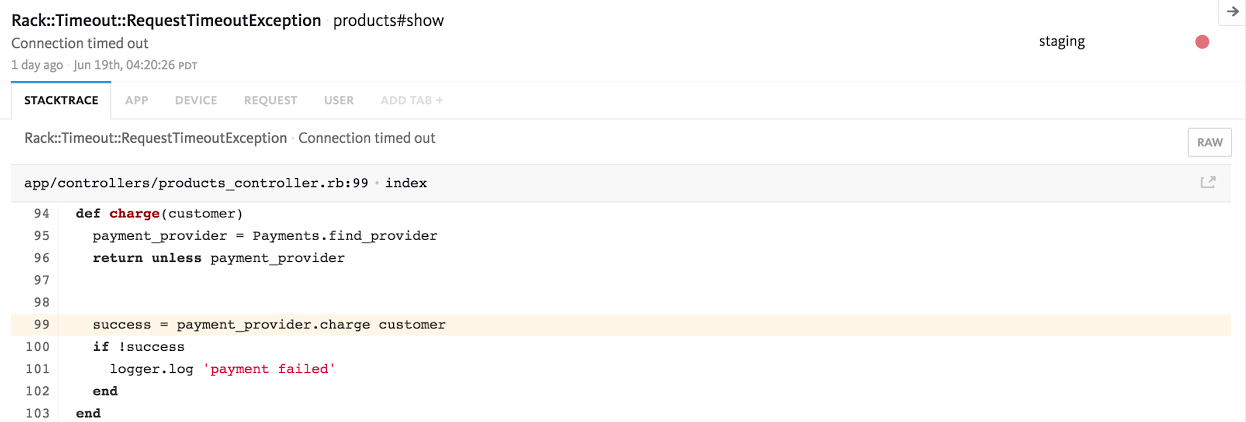
Although a great tool for managers and non-technical people, developers get the most out of using Bugsnag. For any error that occurs, Bugsnag will show you where in the code, when, how often, and which platform it happened + more. Good luck getting all that in a support request.
Add new features as “Sprout Microservices” to limit growth in legacy systems
Suppose you work for a bank that wants to implement a feature to allow business analysts to see how many new customers sign up for each type of bank account. Suppose further that you have a legacy service that does all the heavy lifting of validation, transaction handling and account management. One would think that because we want to record new signups, we would have to write our new code in the account management section of the legacy service. What we can do instead is to make a new microservice; a business-analytics service. This could for example receive requests from the legacy service upon a new customer signup, or periodically monitor the database for new entries and in that way be completely decoupled from the legacy service (but coupled to your database). Either way, the change required in your legacy service is minimal or non-existent. The keen observer will notice that this above example is the architectural equivalent of the Sprout Method/Class technique described in Feathers’ book.
Microservices work the best when developed from an existing monolithic architecture where the domain is well understood, and therefore will often lend itself well to migrating legacy services. That being said, microservices are no silver bullet, and by no means are they a quick fix. There are drawbacks and considerations you will have to take into account before rushing into this style of architecture. I highly recommend Sam Newman’s Building Microservices if you are interested in learning more about this exciting subject.
Legacy code is technical debt that must be managed in one way or another. The recommended approach is still following Michael Feathers’ suggestions, but in recent years new tools and techniques have emerged. Take advantage of these when rewriting legacy code, and take control of your technical debt before it controls you.