Healthier Apps. Better Performance. Delighted
Users.
Happy customers are loyal customers. Our developer‑first observability platform delivers the insights you need to improve application performance while balancing roadmap agility and application stability.
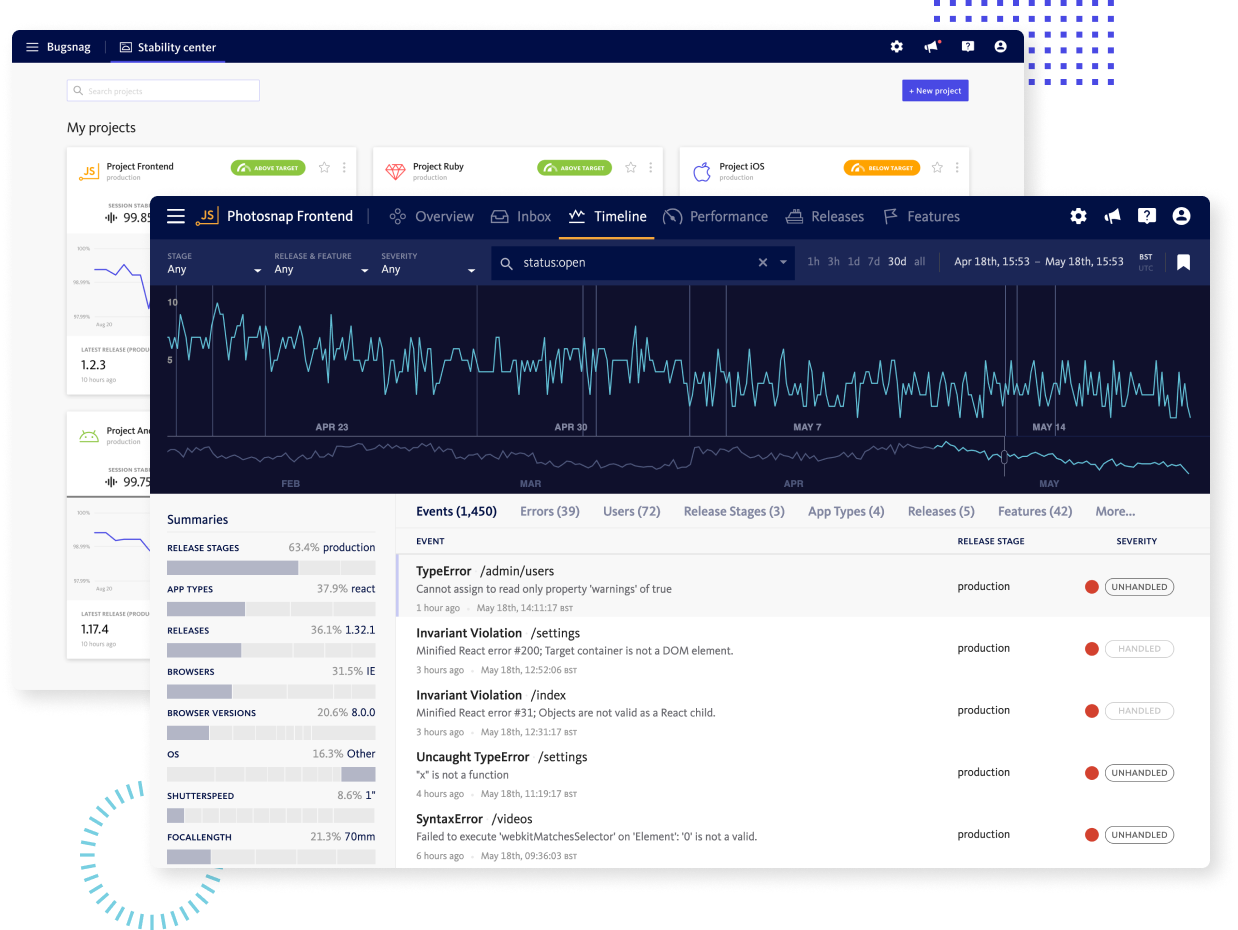
Healthier Apps. Better Performance. Delighted Users.
Happy customers are loyal customers. Our developer‑first observability platform delivers the insights you need to improve application performance while balancing roadmap agility and application stability.
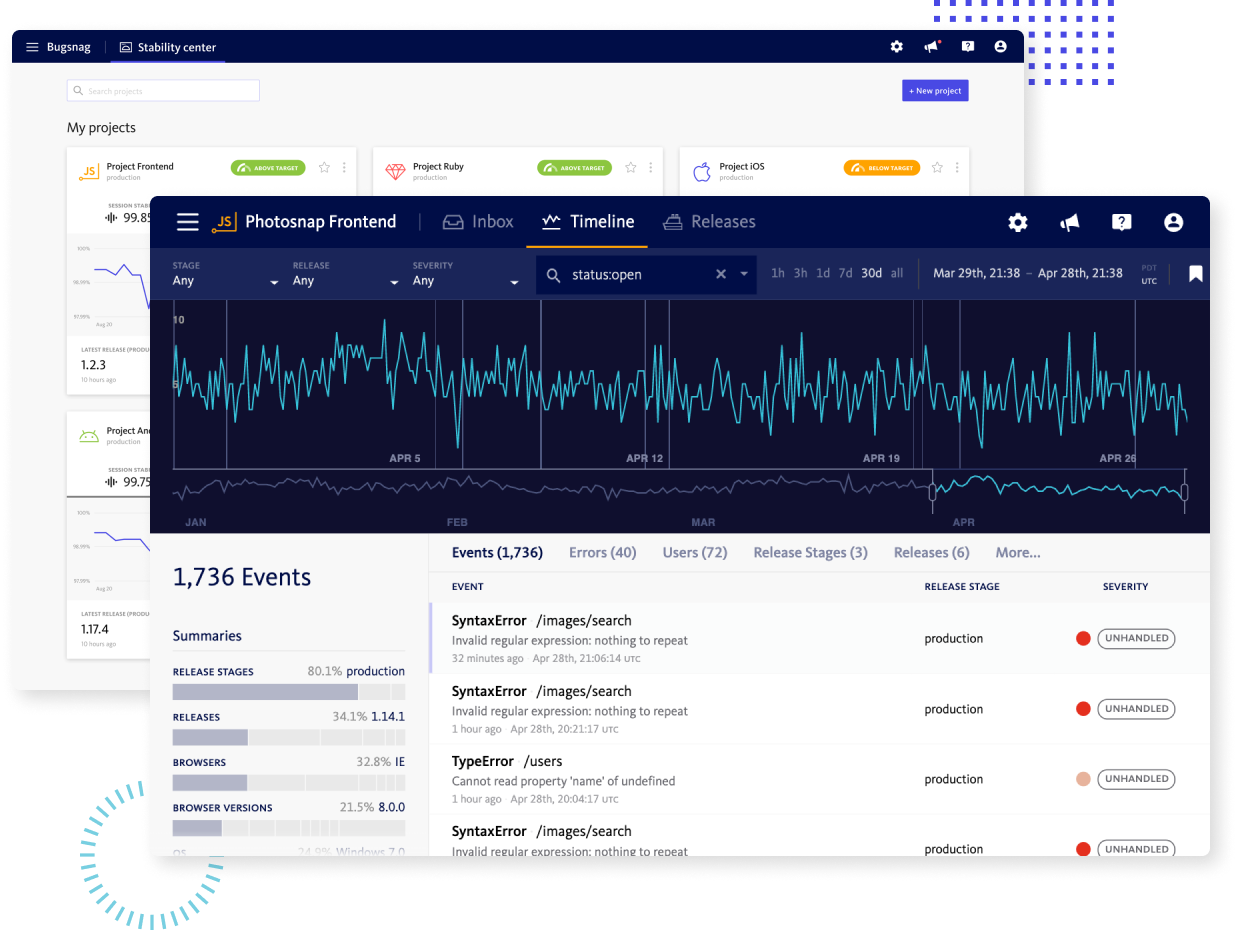

Build Better Apps with Developer-First Observability



Built to handle today's enterprise-scale