
Technical challenges with processing minidumps at large scale
Bugsnag has recently added support for processing minidumps so that customers can track native crashes on Electron or crashes generated when using Breakpad or Crashpad.
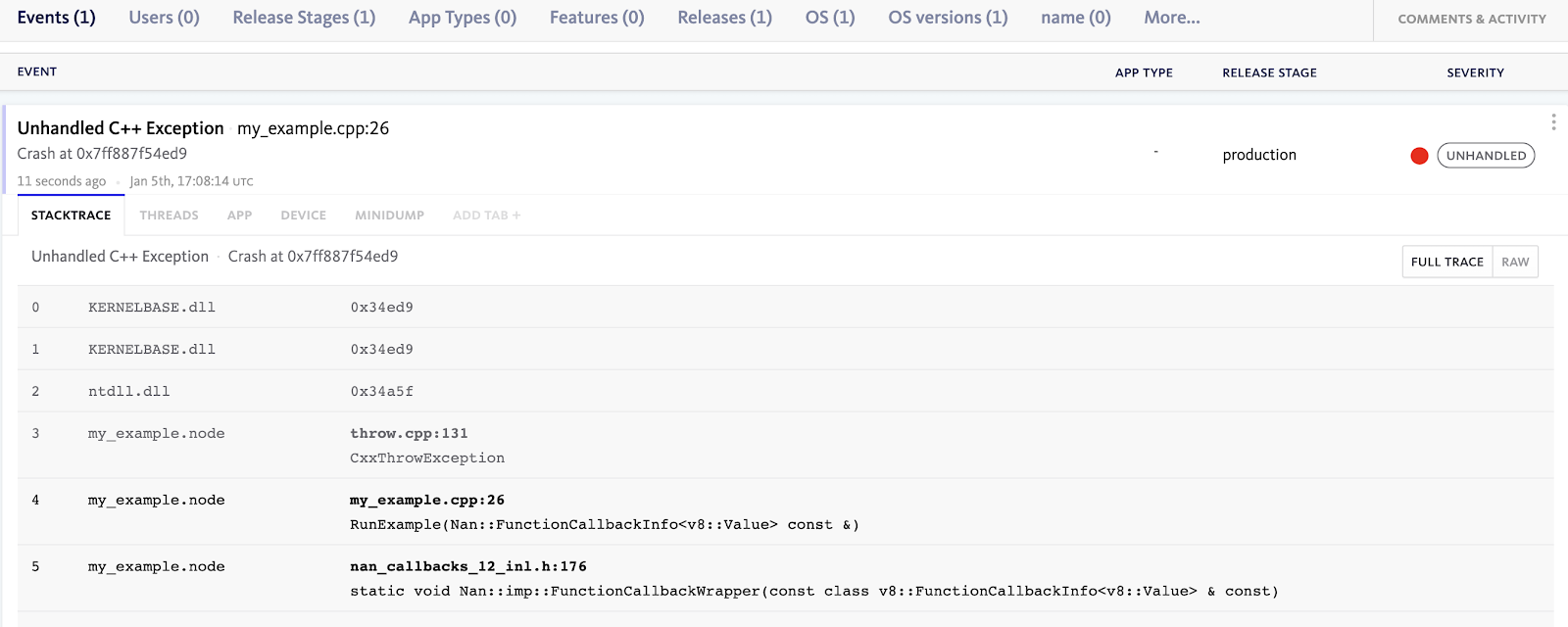
Adding minidump support came with a number of technical challenges that we had to address to ensure that we can process the files in an efficient, scalable manner without affecting our normal error event processing throughput.
What is a minidump?
A minidump is a file that gets generated by some processes when they crash. They are smaller than core dumps and just provide the required data to perform basic debugging operations.
The minidump file format was invented for use in Windows when the OS encounters an unexpected error. Subsequently, tools such as Google’s Breakpad and Crashpad adopted the same format to generate application crash dumps on multiple platforms. Apps built with Electron also generate minidump files for native crashes (since Electron uses Crashpad).
The minidump file contains information about the process at the time of the crash and includes details such as:
- The reason for the dump
- A list of the modules (executables and shared libraries) that were loaded in the process
- Details of the active threads, including the registers and stack contents for each thread
- Metadata about the device (OS version, CPU etc)
How to get useful stack traces from a minidump
Walking the stack
Within the minidump there’s a runtime stack of each active thread (at the time the error occurred) and the register values for those threads. These details can be used to walk the stack and produce a stack trace for each thread. In some cases it’s possible to get a valid (though unsymbolicated) stack trace using this method alone but in other cases we need additional Call Frame Information (CFI) that’s provided within the debug files.
Call Frame Information
Call Frame Information (CFI) records describe how to restore the register values at a particular machine address. This data is generally provided in the debug files and allows a more reliable stack trace to be generated when walking the stack. Without the CFI information the stack walker may need to scan the stack to attempt to find the calling frame but this can be less reliable and can produce invalid stack traces.
Symbolicating the stack trace
Once a stack trace has been obtained it will just contain the addresses of each frame. In order to produce a meaningful stack trace (with the function name, source file, and source line number for each frame) we need to “symbolicate” it, i.e. apply the debug symbols to them. The relevant debug file from the compiler (e.g. dSYMs for macOS) could be used for this, but Breakpad have defined their own symbol file format that can be used instead. The Breakpad symbol file is simpler than most compiler-generated debug files (it doesn’t contain details such as the abstract syntax tree) but provides the required details, in a readable format, to symbolicate the stack trace.
Breakpad Tools
Breakpad provides a number of tools to help with manually processing a minidump or uploading them to a dedicated server/service for processing:
- minidump_stackwalk
Takes in a minidump file and optional Breakpad symbol files and outputs the stack trace for each thread along with other information (such as the reason for the crash, register values for each frame, details of the operating system, etc.). This is a useful tool for parsing minidumps and getting meaningful stack traces from them.
- minidump_dump
Provides more detailed information about the minidump (such as details of each of the streams within the minidump).
- minidump_upload
Uploads minidump files to a dedicated server for processing (such as Bugsnag)
- dump_syms
Generates Breakpad symbol files from the application binary and debug files
- symupload
Uploads Breakpad symbol files to a dedicated server for processing (such as Bugsnag)
An example of the output of the minidump_stackwalk tool with the relevant symbol files can be seen below:
— CODE language-plaintext —
Operating system: Windows NT
10.0.19041 1151
CPU: amd64
family 23 model 24 stepping 1
8 CPUsGPU: UNKNOWN
Crash reason: Unhandled C++ Exception
Crash address: 0x7ff887f54ed9
Process uptime: 4 secondsThread 0 (crashed)
0 KERNELBASE.dll + 0x34ed9rax = 0x655c67616e736775 rdx = 0x6f6d2d6576697461
rcx = 0x6e2d7070635c656d rbx = 0x00007ff87f731600
rsi = 0x000000b80f3fcb70 rdi = 0x000000b80f3fca40
rbp = 0x000000b80f3fca10 rsp = 0x000000b80f3fc8d0
r8 = 0xaaaaaaaa0065646f r9 = 0xaaaaaaaaaaaaaaaa
r10 = 0xaaaaaaaaaaaaaaaa r11 = 0xaaaaaaaaaaaaaaaa
r12 = 0x00007ff87f6f1ba0 r13 = 0x000010ff084af60d
r14 = 0xffffffff00000000 r15 = 0x0000000000000420
rip = 0x00007ff887f54ed9
Found by: given as instruction pointer in context
1 KERNELBASE.dll + 0x34ed9
rbp = 0x000000b80f3fca10 rsp = 0x000000b80f3fc908
rip = 0x00007ff887f54ed9
Found by: stack scanning
2 ntdll.dll + 0x34a5f
rbp = 0x000000b80f3fca10 rsp = 0x000000b80f3fc960
rip = 0x00007ff88a6a4a5f
Found by: stack scanning
3 my_example.node!CxxThrowException [throw.cpp : 131 + 0x14]
rbp = 0x000000b80f3fca10 rsp = 0x000000b80f3fc9b0
rip = 0x00007ff87f6fab75
Found by: stack scanning
4 my_example.node!RunExample(Nan::FunctionCallbackInfo<v8::Value> const &) [my_example.cpp : 26 + 0x22]
rbp = 0x000000b80f3fca10 rsp = 0x000000b80f3fca20
rip = 0x00007ff87f6f1ec2
Found by: call frame info
…
Technical challenges of processing minidumps
We faced a few technical challenges when adding minidump support to Bugsnag. Minidumps vary quite a lot from our usual error event JSON payloads so we had to ensure that we can process them in an efficient, resilient, and scalable manner.
File Size
Minidump files can be much larger than the normal payloads that we receive; our normal payloads average ~20KB whereas minidumps are typically hundreds of kilobytes in size. Additionally, minidumps can get quite large (tens of megabytes) if there are a lot of active threads or threads with large stacks.
Normally when we receive error event payloads we add them to a Kafka queue for asynchronous processing so that we’re able to handle any backlogs with uploads. We needed to make sure that the queuing mechanism would be reliable if we were queuing up larger minidump files. The minidump files compress well (typically to around 10% of their original size) but there was still a risk that the compressed files would be too large.
We did some load testing with messages of various sizes on an internal Kafka instance and found that:
- The data throughput and replication lag weren’t really affected by the size of the files
- The number of messages that could be processed per second decreased as the average file size increased
This decreased message throughput was only significant when simultaneously queuing lots of particularly large files but we anticipate that these should be very rare and therefore Kafka will be suitable for the purpose.
Symbolication Speed
When symbolicating a minidump using Breakpad’s minidump_stackwalk tool it can take a lot longer to process the minidump when the Breakpad symbol files are provided (due to the time it takes to load the symbol files, parse them and look up the relevant symbol data). On a sample Electron minidump it took 20ms without the Breakpad symbol files and 14s with them!
The slower processing time isn’t too much of a concern when manually symbolicating a single minidump but we need to ensure that we can process and symbolicate minidumps as efficiently as possible so that we can maintain a high throughput of minidump processing.
In order to achieve this, we implemented our own symbolication logic. The Breakpad symbol file format is simple and well documented meaning that we can parse the file to produce a bespoke mapping file that allows for easy address lookup. The bespoke file is a lot larger than the Breakpad symbol file but is also a lot more efficient for performing the lookups. Doing this pre-processing of the Breakpad symbol file upfront means that the time taken to process a minidump is significantly reduced (at the cost of increased storage requirements for the symbol files).
Using the Call Frame Information
In the initial design of the minidump processing we omitted the use of Breakpad symbol files altogether when walking the stack (to improve efficiency) but we soon realised that this sometimes resulted in invalid stack traces due to the missing Call Frame Information data. We knew that if we passed in the full Breakpad symbol files for the stack walking it would be slow (due to it trying to symbolicate the stack trace too) so instead we opted for producing a trimmed-down version of the file that just contained the information required for walking the stack. This greatly reduced the size of the Breakpad symbol file as well as the time it took to process the minidump but it still wasn’t very efficient (taking 1.5s for an example Electron minidump).
We therefore explored the option of serializing the trimmed Breakpad symbol file so that it could be read more efficiently (rather than having to parse the file each time). Using a serialized version of the file reduced the processing time from 1.5s to 200ms. This performance improvement means that we should be capable of supporting a higher throughput of minidumps per instance of the service meaning that we can keep infrastructure costs down.
Next Steps
As adoption of the new feature grows we’ll monitor the usage of our infrastructure closely to ensure that we continue to process minidumps in an efficient manner and see whether there are any other performance improvements to be made.